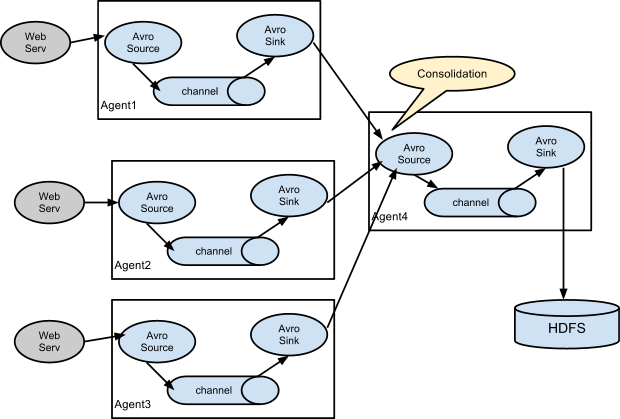
采集日志到消息队列和分布式文件系统
下面是Flume的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| # example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = hdfs-sink kafka-sink console-sink
a1.channels = c1 c2 c3
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
a1.channels.c3.type = memory
a1.channels.c3.capacity = 1000
a1.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2 c3
# Describe the sink
a1.sinks.console-sink.type = logger
a1.sinks.console-sink.channel = c1
a1.sinks.hdfs-sink.channel = c2
a1.sinks.hdfs-sink.type = hdfs
a1.sinks.hdfs-sink.hdfs.path = hdfs://vm01.lan:9000/flume/webdata
a1.sinks.kafka-sink.channel = c3
a1.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka-sink.kafka.topic = app-log
a1.sinks.kafka-sink.kafka.bootstrap.servers = localhost:9092
a1.sinks.kafka-sink.kafka.flumeBatchSize = 20
a1.sinks.kafka-sink.kafka.producer.acks = 1
a1.sinks.kafka-sink.kafka.producer.linger.ms = 1
a1.sinks.kafka-sink.kafka.producer.compression.type = snappy
|
上面的配置表示,日志源是localhost:44444, 采集的日志暂时存放在内存中,然后分别导出到hdfs、kafka和console(终端输出).
一个channel对应一个sink, 一个source可以对应多个channel。
